Creating Enhanced Access to Wexler Oral History Project Interviews
In April 2017, we received a three-year grant from the National Endowment for the Humanities (NEH) that would allow us to make the Yiddish Book Center’s Wexler Oral History Project’s collection more accessible. The project, which will soon be entering its second year, consists of three major components:
- We are transcribing English-language interviews and syncing transcripts to interviews through the Oral History Metadata Synchronizer (OHMS) platform.
- We are indexing each interview, also in OHMS.
- We are updating, expanding, and standardizing our metadata.
By the end of the third year, around 400 interviews will be synced minute-by-minute with their transcripts, and the majority of the collection will have a timecoded index of interview contents.
The added component of searchable transcripts and indices as part of the Project’s archive will make our collection more accessible to the general public, as well as to students, researchers, language pedagogues, filmmakers, and journalists.
In this post, we wanted to explain a bit more about what this work entails, what it will achieve, and give you a glimpse of what the finished product will look like:
Transcripts
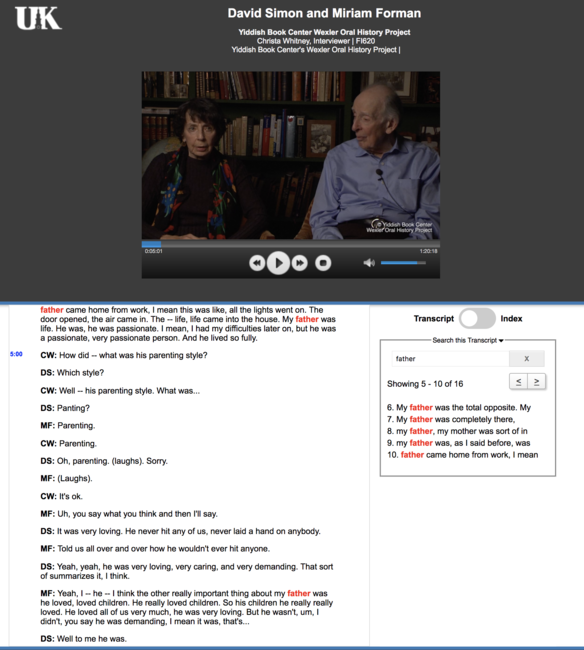
One of the ways our interviews will be made more accessible through this grant-funded project is through transcripts, which will be synced to the interviews minute-by-minute. Here is a glimpse at our process of creating and syncing each transcript: first, we send out each interview to the Audio Transcription Center, in Boston, which transcribes the interview and sends back the transcript. We then copyedit the transcript, making sure it is formatted correctly and error-free. We also fill in all the blanks for Yiddish words, cross-referencing them with our metadata lists. Next, we upload it to OHMS and sync it, minute-by-minute, to the interview. Thanks to this feature, viewers can click on any part of the transcript that interests them, and the video will fast forward to that exact moment in the interview.
Indices
The other way viewers will be able to browse through interviews is with the help of indices, created specifically for each interview. Each index functions as a table of contents of sorts, with short summaries and keywords for each interview section. Where relevant, each interview section will include photographs of artifacts and geotags. For example, if a narrator is talking about their bubbie (grandmother) and has provided us with a photograph of her, we can drop that photograph into the index, so that viewers can see it while hearing stories about her!
Similarly, if a narrator is discussing their ancestral shtetl, we can use geotagging to provide viewers with a small map to view the shtetl’s location while hearing about it in the interview.
The keywords, which will include not only English-language words, names, and places, but also transliterated Yiddish words and names, will allow people to browse interviews thematically and find passages that they might have otherwise missed. For example, someone could talk at length about a partisan fighter in their family without ever using the word “partisan”—thanks to the keywords in the indices, someone searching for partisan stories would be able to find that story.
Examples of Indexing Features

Example of an artifact within an indexed interview. When you click on the "portrait of Meyer Krawetz" hyperlink, it will open up the image of her father. (See next slide.)

The portrait of Meyer Krawetz as it appears when the hyperlink in the index segment is selected.

Example of an indexed interview with geotagging in an index segment. When you click on the hyperlink with the name of the town "Ostrow Mazowiecka," it will open up a map to the geo-coordinates we've specified. (See next slide.)

A map of Ostrow Mazowiecka, which pops up when the geotag in the index segment is selected.

Example of a word search in an indexed interview. You can see all occurrences of the searched word appearing on the right of the index, as well as highlighted in red within the index itself. When you click on the search result, it will take you to that part in index and start playing the interview from that timecoded place in the interview.
Metadata
The third major component of this project is the expansion and standardization of our metadata. To date, we have generated lists of over 600 keywords specific to the project, including names of Yiddish authors, Yiddish words, Yiddish organizations, institutions, and publications, and Eastern European locations. We are utilizing the Merriam-Webster Dictionary, the Getty Thesaurus of Geographic Names, the YIVO Institute for Jewish Research encyclopedia, and other resources to standardize our metadata to aid in searches.
Enhanced Access
Once transcripts are cleaned up and synced to interviews, and indices are created, each interview will be made accessible through a new portal on our website, with the option of toggling back and forth between its transcript and its index; this way, the interviews can be viewed either alongside a word-by-word transcript or by skipping thematically through indices.
This will allow many opportunities for new uses of our collection—for example, if a documentary filmmaker is working on a film about the Warsaw Ghetto, or if an academic is writing about a Yiddish publication, or a musician is researching the work of a specific cantor, they will be able to access the relevant materials in our collection quickly and comprehensively.
How You Can Help
The stories that we have and continue to collect and share through our Wexler Oral History Project contribute invaluable perspectives on Yiddish language, culture, and history. Help us make our ever-growing collection more accessible by contributing to our matching grant fund, so that we can receive the full funds offered by the National Endowment for the Humanities and complete the project by May 2020!
- Read the letter from Aaron Lansky about why this project is important.
- Explore our Wexler Oral History Project collection now by searching for keyword or browsing by name.